📄 FormLens
FormLens: From Ink to Insight with Adapting Vision-Language Models for Handwritten Form Digitization
CVIT, International Institute of Information Technology
To be presented at ICVGIP 2025 (Dec 17 - 20; IIT Mandi, Himachal Pradesh, India.)
Key Contributions
- FormLens: We present FormLens, an adaptation of the vision-language model GOT 2.0, tailored for end-to-end form digitization. FormLens directly transforms full input images into structured key-value pairs, eliminating the need for region detection, OCR, or rule-based processing.
- Real-World Handwritten Form Dataset: We release a new benchmark dataset, Form6000, comprising 6,000 handwritten forms filled by 650 individuals. Collected under real-world conditions with diverse layouts, backgrounds, and orientations, this dataset offers a challenging and practical benchmark for advancing handwritten form digitization.
- Two-Stage Decoder Adaptation Strategy: We develop a two-stage training pipeline for adapting the decoder on generic and domain-specific handwritten data. This improves robustness to layout variations, handwriting styles, and image degradations typically found in real-world settings.
- Strong Empirical Performance: We conduct extensive experiments demonstrating that FormLens consistently outperforms both commercial (e.g., Google Form Parser and Azure Form Recognizer) and open-source form processing systems in accuracy, robustness, and generalization, particularly in unconstrained handwritten scenarios.
Methodology
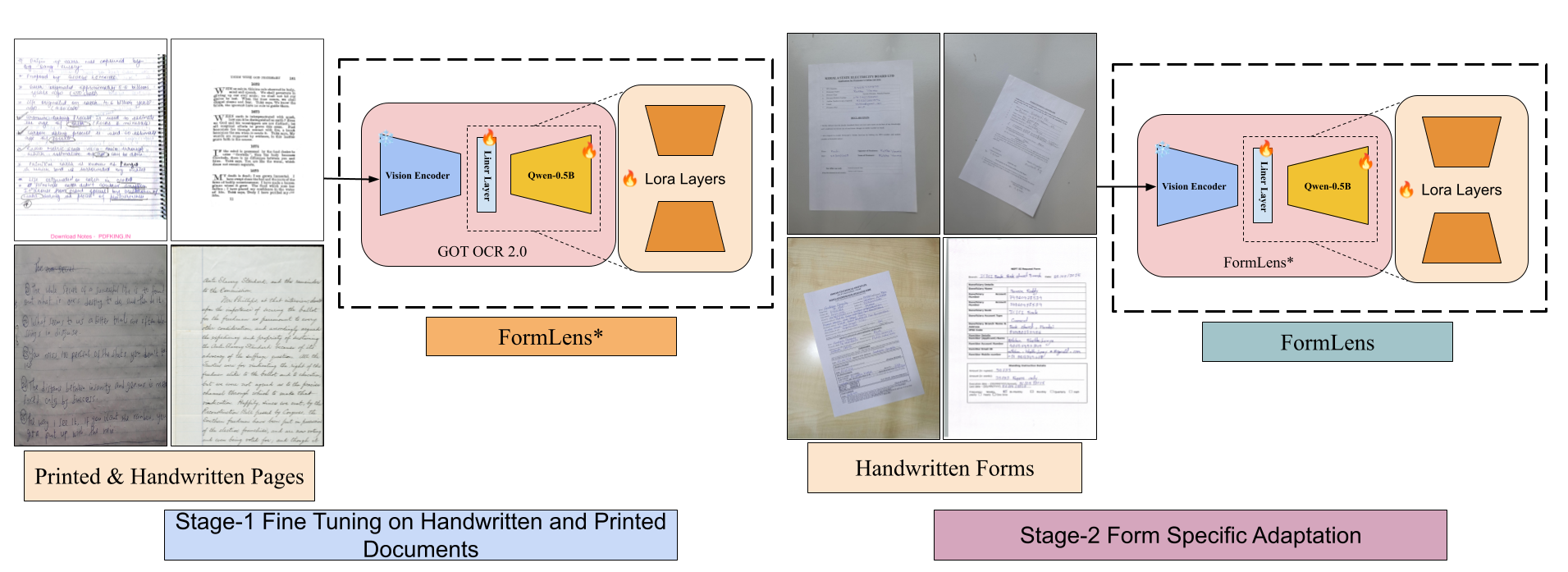
Figure 1: FormLens pipeline overview showing the end-to-end form digitization process.
Form6000 Dataset

Figure 2: Sample forms from the Form6000 dataset showing diverse layouts and handwriting styles.
Dataset Statistics
50
Unique Form Templates
650
Participants
6,000
Total Images
5,350
Mobile Captures
| Characteristic | Count |
|---|---|
| Number of unique form templates | 50 |
| Number of participants (writers) | 650 |
| Forms filled per participant | 1-2 |
| Total handwritten filled forms | 650 |
| Scanned high-resolution forms | 650 |
| Captured mobile images (7-10 per form) | 5,350 |
| Total dataset size (images) | 6,000 |
Results
Performance Comparison
| Method | WRR | CRR | P | R | F1 |
|---|---|---|---|---|---|
| Google Form Parser | 92.14 | 96.38 | 88.90 | 90.45 | 89.67 |
| Azure Form Recognizer | 93.29 | 97.25 | 91.12 | 92.60 | 91.85 |
| PaddleOCR | 35.23 | 64.03 | 52.21 | 48.70 | 50.40 |
| DocTR | 32.22 | 65.44 | 50.93 | 46.28 | 48.50 |
| Donut | 65.33 | 70.12 | 66.45 | 67.21 | 66.83 |
| Naugat | 76.13 | 83.39 | 77.90 | 79.15 | 78.52 |
| FormLens (ours) | 95.44 | 98.33 | 94.12 | 95.31 | 94.71 |

Example 1: FormLens results showing accurate form digitization.

Example 2: FormLens results demonstrating robust performance across different form layouts.
Qualitative Comparison Gallery
Column 1
Captured
Ground Truth
Azure
Google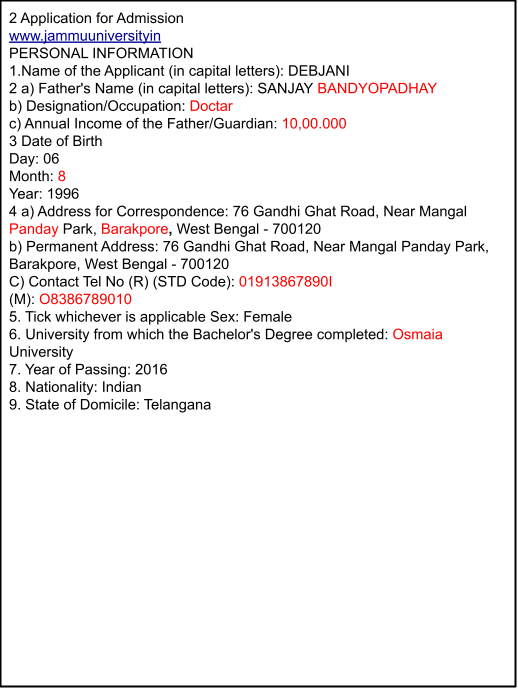
FormLens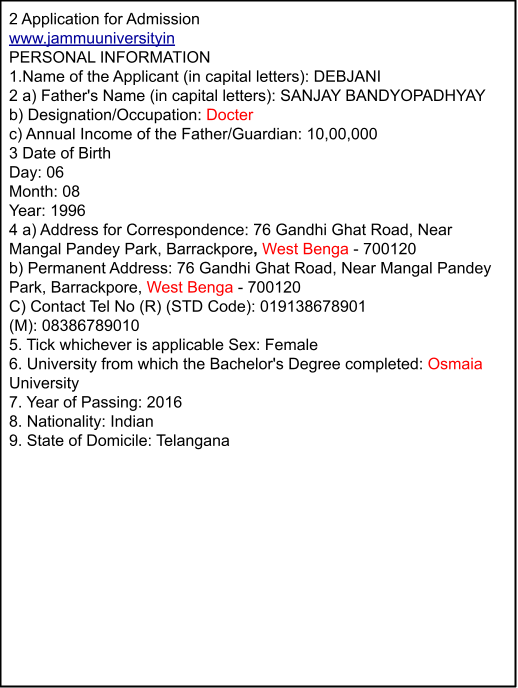
Column 2
Captured
Ground Truth
Azure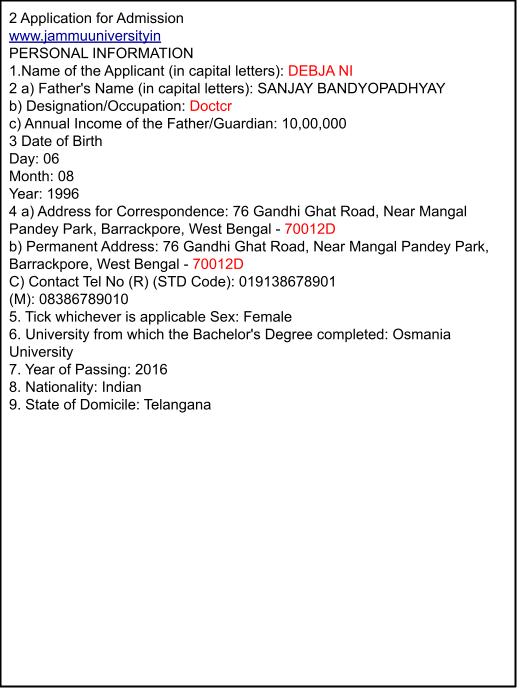
Google
FormLens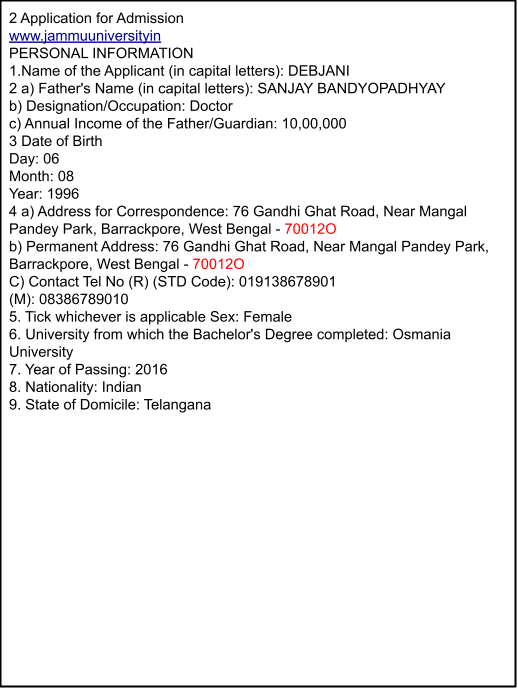
Column 3
Captured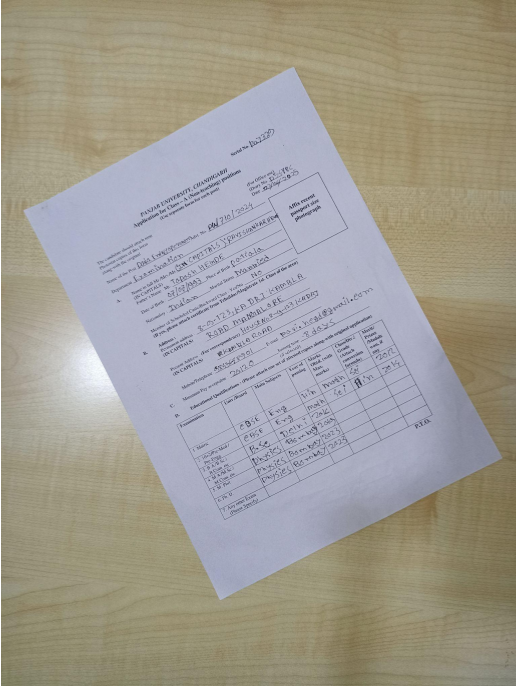
Ground Truth
Azure
Google
FormLens
Column 4
Captured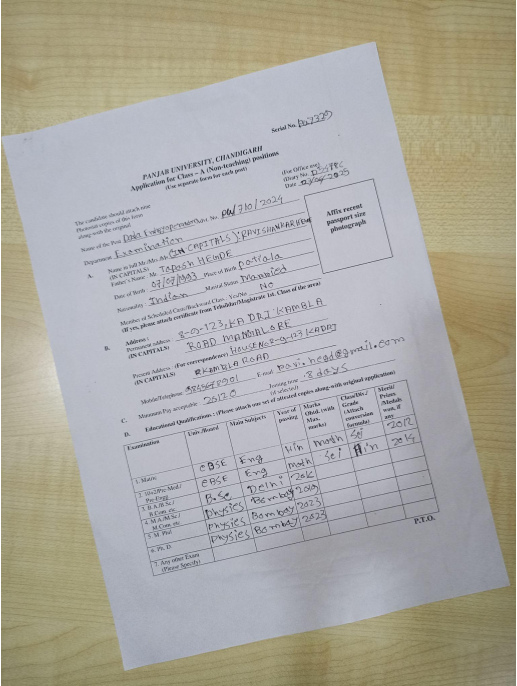
Ground Truth
Azure
Google
FormLens
Column 1
Captured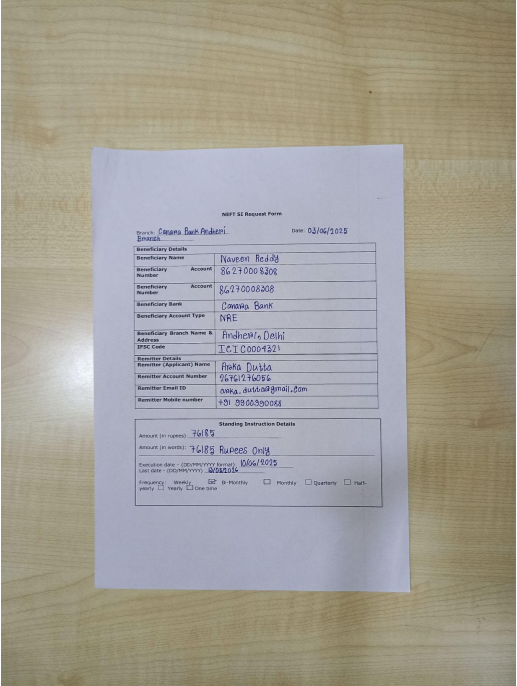
Ground Truth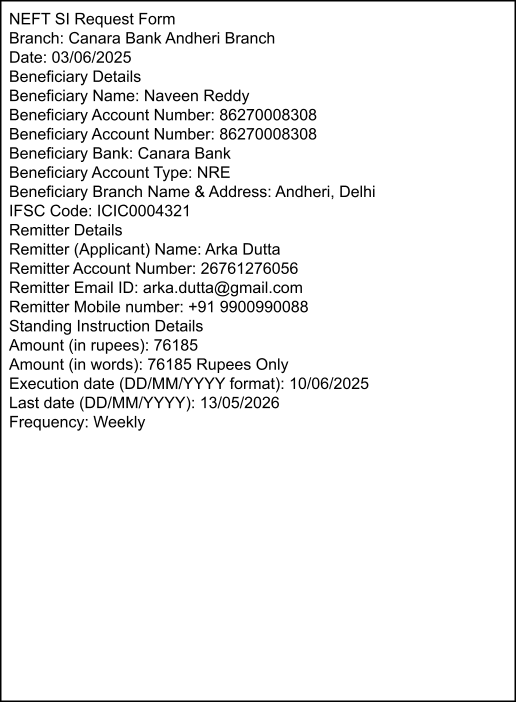
Azure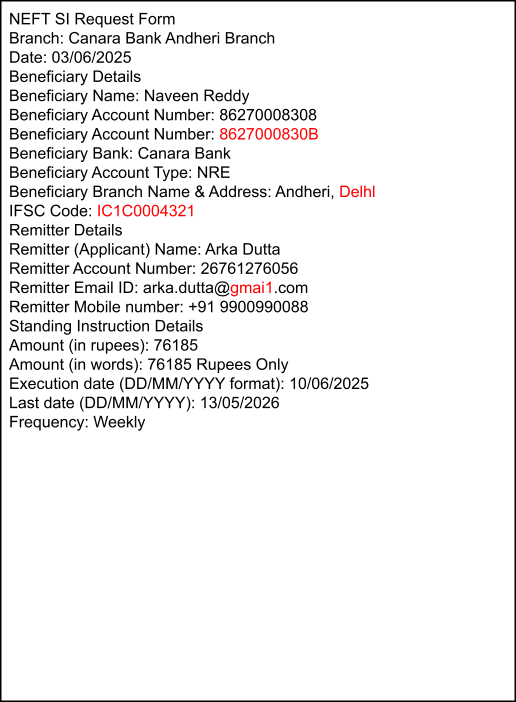
Google
FormLens
Column 2
Captured
Ground Truth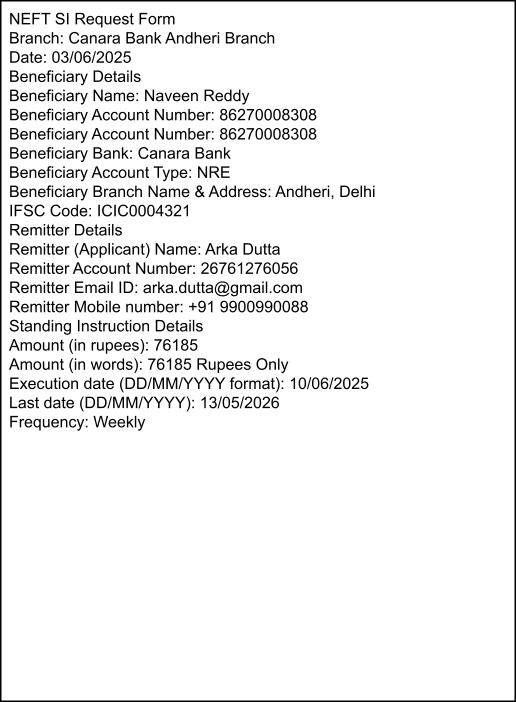
Azure
Google
FormLens
Column 3
Captured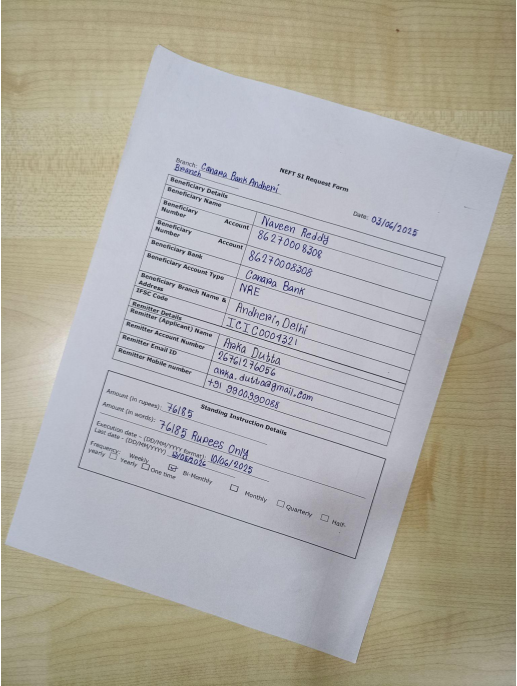
Ground Truth
Azure
Google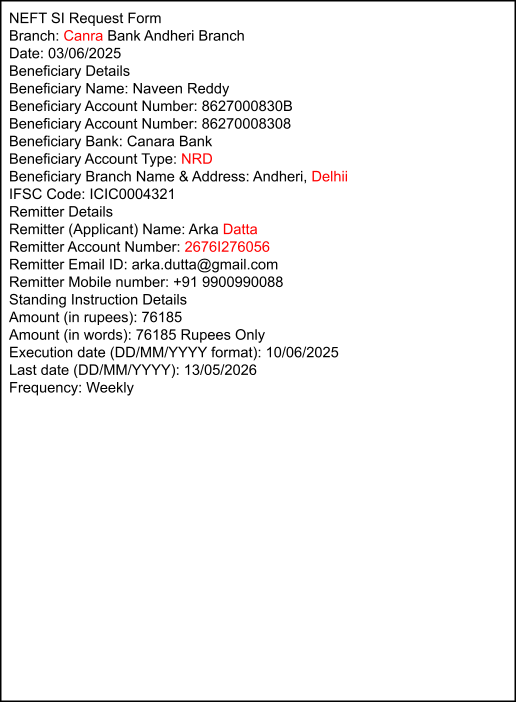
FormLens
Column 4
Captured
Ground Truth
Azure
Google
FormLens
Column 1
Captured
Ground Truth
Azure
Google
FormLens
Column 2
Captured
Ground Truth
Azure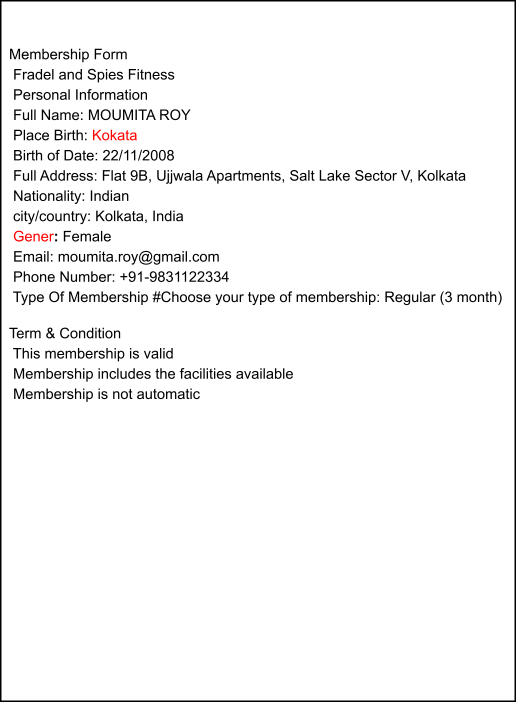
Google
FormLens
Column 3
Captured
Ground Truth
Azure
Google
FormLens
Column 4
Captured
Ground Truth
Azure
Google
FormLens
Live Demo
Try our FormLens model live! Upload your handwritten forms and see the results instantly.
🚀 Try Live DemoDemo Video: FormLens live demonstration showing real-time form digitization capabilities.
Demo Features:
- Upload handwritten form images (JPG, PNG)
- Real-time processing and digitization
- Structured key-value pair extraction
- Download results in JSON format
- Support for various form layouts and handwriting styles
Citation
If you use FormLens in your research, please cite our paper:
@inproceedings{bhattacharyya2025formlens,
title = {FormLens: From Ink to Insight with Adapting Vision-Language Models for Handwritten Form Digitization},
author = {Shaon Bhattacharyya and Ajoy Mondal and C. V. Jawahar},
booktitle = {Proceedings of the 15th Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP)},
year = {2025},
address = {IIT Mandi, India},
pages = {1--8},
organization = {ACM / Springer},
institution = {Centre for Visual Information Technology (CVIT), IIIT Hyderabad},
note = {Accepted paper, 8 pages, double-column format}
}
📄 Publication Details:
- Conference: 16th Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP)
- Year: 2025
- Venue: IIT Mandi, India
- Publisher: ACM / Springer
- Status: Accepted paper, 8 pages, double-column format
- Institution: Centre for Visual Information Technology (CVIT), IIIT Hyderabad
© 2025 FormLens Project. All rights reserved.